سیاست و
بازاریابی - جلوههای جدیدی که در اپلیکیشنهای مختلف موبایل، بهویژه در حوزهی ویدئو میبینیم، دنیایی از هوش مصنوعی را در پسِ خود دارند.
ماسکها، عینکها، کلاهها و انواع دیگر محتوای مجازی که در اپلیکیشنهای مختلف از
اینستاگرام گرفته تا یوتیوب استوریز روی چهرههای کاربران اضافه میشوند، جذابیت و زیبایی خاصی دارند. تابهحال از خود پرسیدهاید این جلوهها چگونه اجرا میشوند؟ بخش هوش مصنوعی گوگل بهتازگی مقالهای دربارهی همین جلوهها منتشر کرده که جزئیات آن را به بهترین نحو برای علاقهمندان توضیح میدهد. مهندسان شاغل در مانتین ویو در مقالهای بلند، جزئیات فناوری هوش مصنوعی در هستهی استوری اپلیکیشنهای مختلف را فاش و نکاتی نیز دربارهی API مشهور آن ARCore ذکر کردند. طبق ادعای آنها، API مذکور میتواند انواع حالات از بازتاب نور محیط تا حالت چهره و حتی بازتاب نور از هر چهره را شبیهسازی کند. همهی آن موارد هم فقط به کمک دوربین و بهطور زنده اتفاق میافتند. آرتیسام آبلاواتسکی و ایوان گریشنکو، متخصصان گوگل در بخش هوش مصنوعی، در مقالهی خود توضیح میدهند: یکی از مشکلات اصلی در تولید قابلیتهای واقعیت افزوده، قراردادن محتوای مجازی در تصاویر دنیای واقعی است. آن فرایند به چندین فناوری بههمپیوسته نیاز دارد که توانایی ردگیری هندسهی سطوح در حالتهای بسیار پویای چهرهی افراد را داشته باشند؛ حالتهایی همچون خنده یا اخم یا پوزخند که هرکدام تغییراتی در سطوح چهرهی افراد ایجاد میکنند.

بخش اختصاصی گوگل در حوزهی واقعیت افزوده ، از فناوری TensorFlow Lite استفاده میکند. آن فناوری نمونهای سبک از فریمورک یادگیری ماشین گوگل بهنام TensorFlow محسوب میشود که برای کاربردهای خاص بهینهسازی شد. در موقعیتهای مناسب، آنها از پردازش بهینهسازیشدهی سختافزارها بهره میبرند که دو شبکهی عصبی را باهم ترکیب میکند. اولین شبکهی عصبی در فناوری اشارهشده تشخیصدهنده است که روی دادههای دوربین فعالیت و موقعیتهای چهره را پردازش میکند. شبکهی دوم مدل مِش سهبعدی نام دارد که از دادههای دریافتشدهی موقعیتی، برای پیشبینی هندسهی سطوح بهره میبرد. چرا از رویکردی با دو مدل استفاده میشود؟ متخصصان گوگل دو دلیل را برای آن توضیح میدهند. استفاده از آن رویکرد نیاز به تقویت دیتاسِت با دادههای مصنوعی را کاهش میدهد و درنتیجه، سیستم هوش مصنوعی میتواند حداکثر ظرفیت خود را برای بهبود پیشبینی مختصات مِش بهکار گیرد. هر دو بخش، برای جانمایی دقیق محتوای مجازی در جلوهها حیاتی هستند. مرحلهی بعدی، مستلزم اجرای شبکهی مِش در یک فریم تصویر دوربین است. تکنیک خاصی باید برای آن مرحله استفاده شود تا تأخیر در تصویر و اختلال آن را کاهش دهد. مِش مدنظر از فریمهای ویدئویی بریدهشده تولید میشود و مختصات را در دادههای واقعی پیشبینی میکند. درنتیجه، موقعیتهای سهبعدی و نیز احتمالات صورتهای موجود در تصویر در فریمهایی با جانمایی مقبول ارائه میشود.
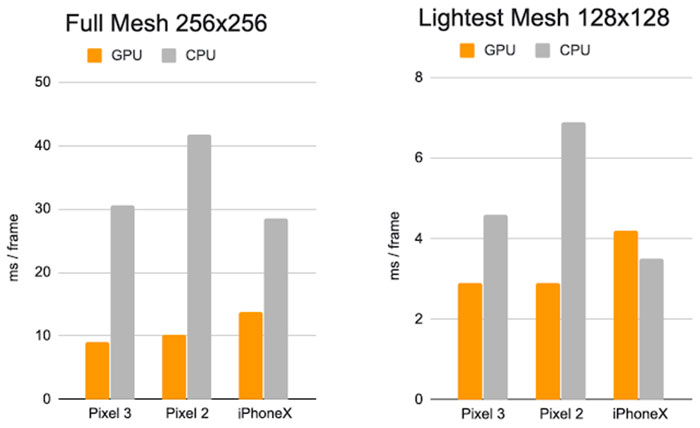
بهرهگیری از شبکهی عصبی پردازش موردنیاز برای تولید جلوهها را بهینه میکند
بهبود کارایی و دقت در پروژههای AR، نتیجهی بهرهگیری بهینه از TensorFlow Lite هستند که نویسندگان مقالهی مذکور اعتقاد دارند درکنار بهبود کارایی، به کاهش مصرف انرژی هم منجر میشود. بهعلاوه، آنها نتیجهی روندی هستند که پیشبینی مدل مِشها را بهینهسازی و درنهایت، به تیمها در مقابله با مشکلات خاص تصویرسازی کمک میکند. این مشکلات از حالتهای چهرهها یا وضعیت نامناسب دوربین یا نور ایجاد میشوند. نکتهی درخورتوجه آن است که مسیرهای جدید پردازش واقعیت افزوده، فقط به یک یا دو مدل بسنده نمیکنند؛ درعوض، از تعدادی معماری خاص استفاده میکنند که با هدف پشتیبانی از دستگاههای متنوع طراحی شدهاند. بهعنوان مثال، نمونههای سبکتر به حافظه و قدرت پردازش کمتری نیاز دارند و درنتیجه، رزولوشن موردنیاز برای ورودی آنها نیز کمتر (128 در 128) خواهد بود. البته، مدلهای پیچیدهتر تا رزولوشن 256 در 256 را پردازش میکنند. طبق تحقیقات نویسندگان مقاله، سریعترین مدل مِش کامل در طرح آنها، زمان پردازشی برابر با 10 میلیثانیه دارد که روی گوشی گوگل پیکسل 3 آزمایش شد. اجرای مدل سبکتر زمان را به 3 میلیثانیه کاهش داد. آزمایش نمونهها روی آیفون X فقط کمی کُندتر بود: نمونهی سبکتر با بهرهگیری از GPU، پردازش را در 4 میلیثانیه برای هر فریم انجام داد و نمونهی سنگین و پیچیدهتر، مِش کامل را در 14 ثانیه آماده کرد.
http://www.PoliticalMarketing.ir/fa/News/66890/گوگل-و-هوش-مصنوعی-درگیر-انیمیشنهای-واقعیت-افزوده-هستند